· Synx Data Labs
When Open Source Isn’t Enough: Rethinking MPP in the AI Era
Explore how enterprises evolve from open-source MPP databases toward enterprise-grade and cloud-native data platforms for AI-era workloads.
As enterprises modernize their data infrastructure, one reality becomes increasingly clear:
Architecture—not just technology—defines the ceiling of data-driven growth.
In earlier discussions, we explored:
- Why organizations are actively replacing Greenplum
- Why Apache Cloudberry has emerged as the leading open-source alternative
But a critical question remains:
What happens when open source alone is no longer enough?
As data complexity grows and AI-driven workloads accelerate, enterprises are moving beyond traditional MPP architectures toward enterprise-grade and cloud-native data platforms.
This article explores that evolution—and what comes next.
The Open-Source Foundation: Apache Cloudberry
In today’s data warehouse landscape, Apache Cloudberry (Incubating) stands out as one of the most advanced open-source MPP databases available.
Built on PostgreSQL 14.4, it delivers a mature and reliable query engine, high-performance parallel execution, and strong compatibility with the Greenplum ecosystem. As an Apache Incubator project, it also provides the transparency and flexibility that many engineering-driven organizations value.
For teams with strong in-house capabilities and a preference for open systems, Cloudberry offers a powerful and cost-efficient analytical foundation. It demonstrates just how far open source can go in supporting large-scale data workloads.
But like all open systems, it is designed to be general-purpose—not fully optimized for every enterprise scenario.
Where MPP Architectures Reach Their Limits
MPP architectures remain highly effective for large-scale analytics.
However, as enterprise requirements evolve, their boundaries become more visible—not as flaws, but as limits of what they were originally designed to handle.
From a user’s perspective, these limits are most noticeable across workloads, operations, and cloud adoption.
At the workload level, MPP systems are optimized for high-throughput, batch-oriented processing.
They excel at complex queries over large datasets, but are less suited for scenarios requiring high concurrency and low latency. As interactive queries, real-time dashboards, and API-driven access become more common, short queries and high-QPS workloads can be harder to support efficiently.
Mixed workloads further increase pressure.
When ETL, BI, and ad-hoc queries share the same cluster, resource contention is difficult to avoid. A single long-running query can impact overall performance, and isolating workloads often means deploying additional clusters—introducing data duplication and synchronization overhead.
Real-time use cases add another layer of complexity.
While MPP systems support incremental processing, they are still primarily designed around batch ingestion, making low-latency pipelines more challenging to implement without additional components.
Operationally, these challenges become more apparent at scale.
Because data is distributed across nodes, failure recovery and scaling operations tend to affect the entire cluster. Expanding capacity often requires data reshuffling, which can temporarily impact performance.
At the same time, data distribution remains an expertise-driven task.
Imbalanced distribution can lead to performance degradation, and diagnosing issues such as data skew or slow queries often requires deep system knowledge, increasing operational overhead.
From a cloud strategy perspective, the gap becomes clearer.
Cloud environments emphasize elasticity and decoupled storage and compute, while traditional MPP systems rely on tightly coupled architectures. This makes it harder to scale resources independently, fully leverage object storage, or integrate seamlessly with cloud-native ecosystems.
Individually, these trade-offs are manageable.
But as workloads become more real-time, concurrent, and AI-driven, they increasingly influence architectural choices—and signal when extending MPP may no longer be sufficient.
When Open Source Isn’t Enough: Two Evolution Paths
As these limitations begin to impact real workloads and operations, the question is no longer whether MPP works—but how far it can be extended.
When open-source MPP solutions can no longer fully meet enterprise demands, organizations typically move in one of two directions.
Some choose to extend the existing architecture, preserving their investment in MPP while strengthening it for production use. Others take a more fundamental step, adopting cloud-native architectures that address these constraints at the architectural level.
Path One: Extending MPP with SynxDB MPP
For organizations prioritizing stability and continuity, extending existing MPP systems is often the most pragmatic path.
This is where SynxDB MPP comes in.
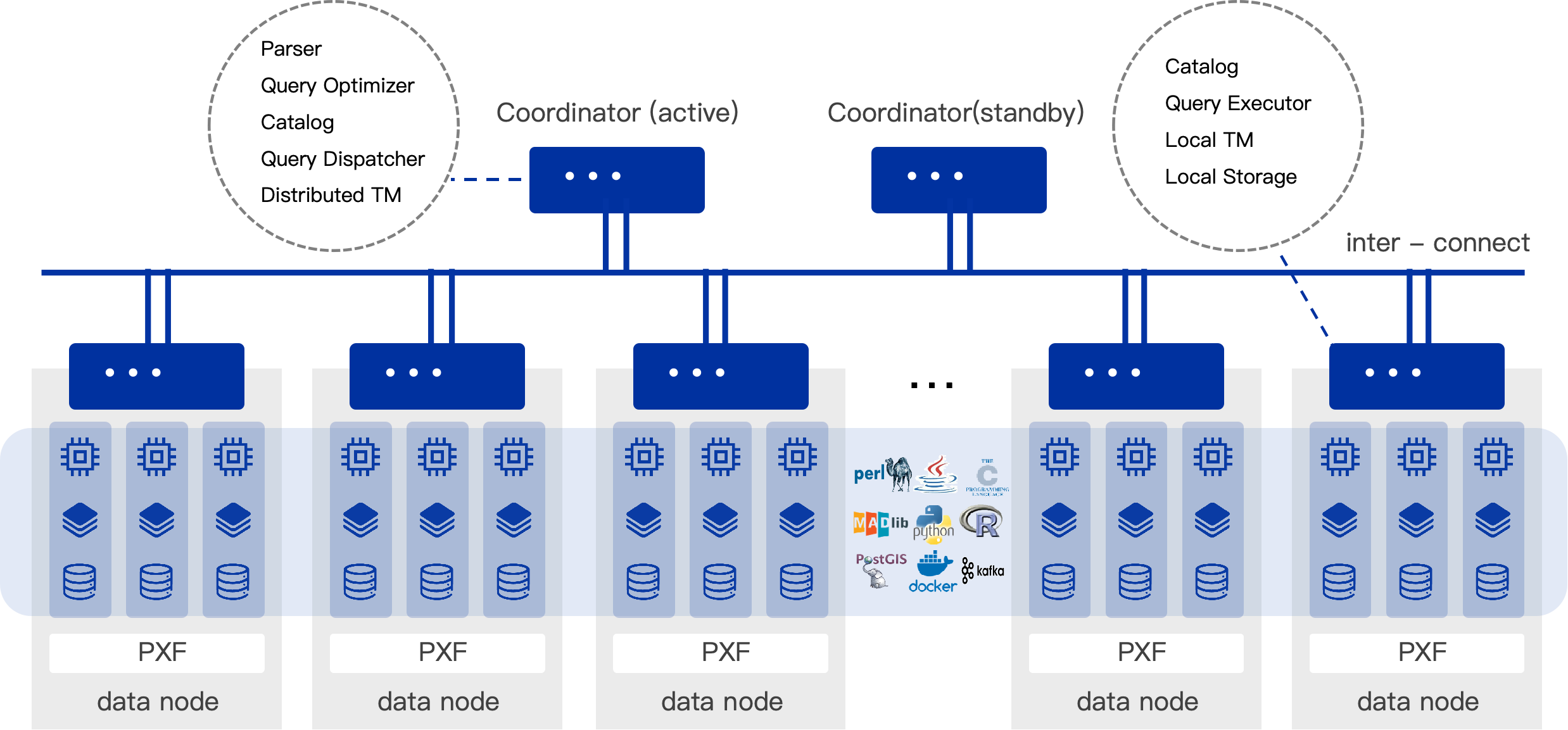
Built on Apache Cloudberry 2.x (PostgreSQL 14.y), SynxDB remains fully compatible with the open-source ecosystem, enabling teams to upgrade without re-architecting their existing data stack. Rather than introducing a new paradigm, it strengthens MPP for production-grade use.
Reliability is no longer dependent on external tooling. Built-in mechanisms such as cross-cluster replication (CBDR) and an automated control plane (DBCC) handle failure detection and recovery, improving system resilience under real operational pressure.
Security and governance are also integrated at the platform level, with capabilities such as transparent encryption, dynamic masking, and fine-grained access control embedded directly into the database engine. This reduces reliance on surrounding infrastructure and simplifies compliance.
From an operational standpoint, SynxDB introduces the predictability often missing in open-source deployments, supported by SLA-backed services and production-grade monitoring.
In this sense, SynxDB MPP is not a departure from Cloudberry, but its enterprise-grade completion.
Importantly, it also extends into AI scenarios through SynxML, enabling vector processing and integration with machine learning frameworks—ensuring MPP-based systems can still participate in emerging AI workloads.
Path Two: Moving Beyond MPP with SynxDB Cloud
However, some challenges cannot be fully addressed by extending MPP.
As workloads shift toward real-time analytics, mixed workload execution, and deeper AI integration, the constraints of tightly coupled architectures become more visible. At this stage, incremental optimization is no longer sufficient—the architecture itself needs to evolve.
This is the rationale behind SynxDB Cloud.
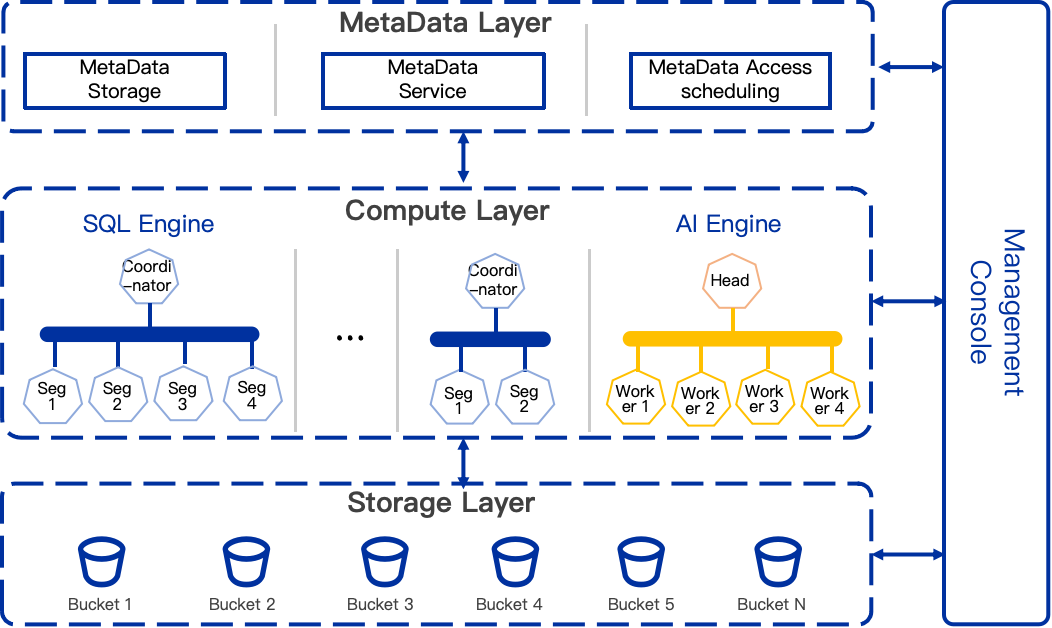
As a next-generation cloud-native data platform (pre-launch), SynxDB Cloud is designed to remove MPP constraints rather than optimize within them. Its core shift lies in full decoupling of storage, compute, and metadata.
Data is persisted in scalable object storage, while compute becomes stateless and independently scalable. This enables near-instant elasticity without costly data redistribution.
Concurrency is also fundamentally redesigned. With shared storage and unified metadata, multiple compute clusters can operate on the same dataset simultaneously, supporting different workloads such as ETL, BI, and ad-hoc analytics without resource contention or data duplication.
This represents more than performance improvement—it changes the operating model.
At the capability level, SynxDB Cloud maintains the same AI support via SynxML as SynxDB MPP, including vector processing and integration with machine learning frameworks for RAG and LLM-based workloads.
The key difference lies not in what is supported, but in how efficiently it scales. With decoupled architecture and multi-cluster concurrency, AI and analytical workloads can run in parallel without interfering with each other.
In this sense, SynxDB Cloud does not introduce new AI capabilities—but provides a more elastic and scalable foundation to operationalize them.
Choosing the Right Architecture
At this stage, the decision is no longer about choosing a database.
It is about choosing architecture.
If your priority is stability, governance, and incremental evolution, extending MPP with SynxDB is a natural path. If your workloads demand elasticity, high concurrency, and deep AI integration, then a cloud-native architecture like SynxDB Cloud becomes the more forward-looking choice.
| Scenario | Recommended Solution | Why |
|---|---|---|
| Open-source, self-managed analytics | Apache Cloudberry | Flexible, cost-efficient, strong MPP foundation |
| Enterprise-grade production workloads | SynxDB MPP | Adds security, HA, and operational guarantees |
| Cloud-native + AI-driven architecture | SynxDB Cloud | Solves scalability, concurrency, and AI integration |
Conclusion: Architecture Defines the Future
The evolution of data platforms is not about replacing technologies—it is about aligning architecture with reality.
Open-source MPP systems like Apache Cloudberry provide a strong foundation.
Enterprise platforms like SynxDB make that foundation production-ready.
Cloud-native systems like SynxDB Cloud push beyond those limits entirely.
Different stages require different architectures.
Related Resources
If you’re evaluating long-term alternatives to Greenplum or planning a migration strategy, these resources may help:
-
Greenplum Alternative: What the Licensing Change Means for Open Source Users — Understand what recent ecosystem changes mean for open source users and long-term infrastructure planning.
-
Why Apache Cloudberry Is the Most Natural Open Source Alternative to Greenplum — Learn why Apache Cloudberry is emerging as a vendor-neutral successor with architectural continuity.
-
SynxDB vs Greenplum Benchmark — Compare performance characteristics and benchmark considerations for modern MPP analytics workloads.
-
Greenplum to SynxDB Migration Guide — A practical guide to planning and executing a smooth migration with minimal disruption.